

Want to make your own AI song covers quick? Need to clone a voice and apply it to a speech or a song and make it sound realistic? Here is where the Retrieval based Voice Conversion WebUI by RVC-Project comes in handy! In this guide for beginners you will learn step-by-step how to train your first cloned voice model and convert one voice to another using AI with ease. Ready? Let’s begin the tutorial!
This guide is divided into three main parts – installing the RVC WebUI, training a voice model (cloning a voice), and model inference (converting one voice to another). You can use the table of contents above to skip between different sections!
Check out also: Stable Diffusion WebUI Settings Explained – Quick Beginners Guide
What Do You Need To Get Started With Voice Cloning?
Retrieval based Voice Conversion WebUI is an amazing tool made available by RVC-Project that we will be using in this tutorial. The software is available for free under the MIT software license, and you can download it either from their official GitHub repository, or from the Huggingface repository here.
Aside from the installed RVC WebUI on your system, you will need samples of the voice that you wish to clone. Move on to see how exactly the recorded voice audio files should be formatted to begin the training process, and how to install the RVC WebUI on your system!
How Much Voice Audio Do You Need for Voice Training / Cloning?
When it comes to the RVC WebUI, you will need anywhere from around 10 minutes to 1 hour of high quality clear voice recordings. Shorter vocal datasets can generally yield less satisfying results.
Of course, you can attempt to use less the recommended amount, or way more (which in some cases is not worth it). There is no golden mean here, so feel free to experiment!
The vocal samples used for training should not have any kind of reverb/delay/echo effect applied to them. If they do, you won’t be able to train your chosen voice accurately.
In our case, we used around 12 minutes of high quality isolated vocals to train our first model, and it came out pretty good (scroll down for an example).
Where can you find some clean and high quality vocals for testing the voice cloning capabilities of the RVC WebUI? – you might ask. So, here is our answer.
In general, one of the best sources for this kind of data are collections of game character voicelines from various video games, which you can find all over the internet. These can prove themselves very useful if you don’t want, or simply can’t record your own vocal samples to experiment with.
In the next paragraph, we’ll explain what kind of recordings you can and cannot use for efficient voice training using RVC.
How To Prepare The Vocal Training Dataset?
RVC WebUI takes in an .wav or .mp3 audio file to source the data for the training process. You supply it to the WebUI by specifying a filepath to your prepared audio file.
The audio files supplied for the training process should be clear and high quality voice recordings (singing voice or speech), that do not contain any instrumental content, don’t feature any kind of background noise, and do not have excessive audio FX applied to them.
Do you have to split up a long audio file before training? No, this is not necessary when using the RVC WebUI. Long audio files will simply get automatically cut up into 4 second samples during processing.
Here are some very important things regarding the input material / your training data:
-
- Ensure that the voice that you’re trying to clone doesn’t have any kind of reverb, delay or echo effect applied to it.
-
- Remove any kind of background noise from your training audio. This is very important.
- Cut out prolonged silent parts from the training audio file (a second or two seconds of silence in between voice lines is usually fine).
- If you’re taking acapella vocals from a song, keep in mind that solo vocals work best. If the vocals are harmonized (or there is more than 1 recorded voice audible at the time), your chances of training a quality model get lower.
- The quality of your chosen voice samples is almost always more important than their quantity. A good quality 15 minute vocal recording is better than low quality unchecked 1 hour long voice audio dump.
If you adhere to these rules, you will get the best results provided you get all the remaining settings right. Let’s now move on to the actual training process!
How To Install The RVC WebUI? – The Quickest Way
There are basically two ways of installing the Retrieval based Voice Conversion WebUI. For both of these you will need to have Python installed on your system, the recommended version being everything above 3.8. If you’re on Windows, then you’ll also need to have ffmpeg installed.
Keep in mind that while we know that the RVC WebUI functions on Windows and Linux without trouble, there are no guarantees that it will work on MacOS without further tweaks.
First method – If you’re a GitHub user: Clone the RVC WebUI files from their official GitHub repository onto your system, install the needed dependencies using the requirements.txt file and run the software using the go-web.bat file.
You can do this by using the following commands after opening a system terminal with administrator privileges in the location you want to install the RVC WebUI in.
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/
pip install -r requirements.txtAfter the dependencies have finished installing without any errors, you will need to download additional models that the RVC WebUI needs for both the training and voice conversion processes. Without these, the WebUI won’t be able to do its work.
Download the files with the models inside, from the RVC WebUI Huggingface repository here. You need the following files: hubert_base.pt, pretrained, uvr5_weights and pretrained_v2.
After downloading these, move them over to the folder you’ve cloned the RVC WebUI files into. Now you should be good to go.
To start the WebUI, on Windows double click the go-web.bat file to start up the WebUI, and on Linux run the infer-web.py script.
The easier & quicker way – If you don’t use GitHub:
Here you will just need to download the RVC-beta.7z file from the RVC WebUI Huggingface repository. This ~5GB archive will contain all the files you need from the get go, including all the necessary model files.
Now, extract the RVC-beta.7z file into the directory of your choice.
Open a system terminal with administrator privileges in the directory you’ve extracted the RVC-beta.7z file to, and run the following command to install the dependencies needed to run the RVC WebUI.
pip install -r requirements.txtNow, all you need to do is to run the go-web.bat file to start the WebUI if you’re using Windows, and run the infer-web.py script if you’re on Linux.
If you’re having any trouble with the installation process, you can also check out the official installation guide in the RVC repository here.
How To Train a Voice Model Using The RVC WebUI – 3 Step Guide
Let’s now go over all the steps necessary to get through the training process from start to finish and create and train a model based on your chosen recorded acapella vocals.
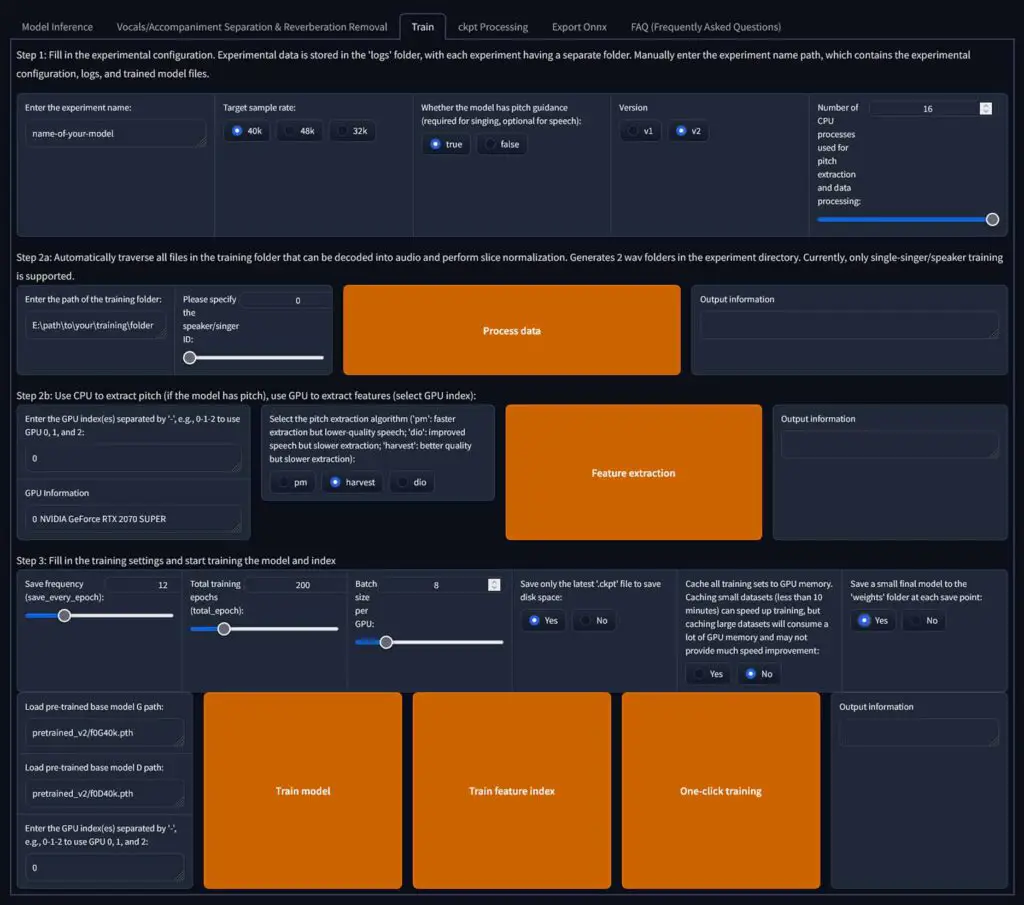
Step 1: Enter the initial settings
First, enter the name you want to choose for the model that you’re about to train in the “Enter the experiment name” field on top the top left of the main RVC WebUI screen.
Then, click on the following settings (these are the settings we found best for a good starting point):
-
- Target sample rate: 40k
- Pitch guidance: True
- Model architecture: v2
- Threads for CPU: The max amount you can choose on your system (if you’re facing crashes during initial processing, you can lower this number).
Step 2: Load and process the training audio data
In the field labeled “Enter the path of the training folder”, enter the path to the directory with the voice audio sample/samples that you wish to use for training. The folder with the training audio should contain only the audio files that you want to use to train your new voice model. It can contain multiple audio files, or single long audio file – it doesn’t really matter.
If you want a shortcut for getting the current directory path in the default Windows system file browser, simply right click the address bar in the top of the file browser window, and choose the option “Copy address as text”.
Now, click the large “Process data” button. This process will take a short while.
Once the data processing finishes, it’s time to move on to the automatic feature extraction.
Select the “harvest” pitch extraction algorithm, then click the “Feature extraction” button and wait until the process finishes.
Time for the very last step – the actual model training process!
Step 3: Train your very first voice model
Now, a few final settings before we hit that training button.
Set the “Save frequency (save_every_epoch)” to 12.
Then comes the time for setting the number of training epochs in the “Total training epochs (total_epoch)” field. In general, if your audio training material is of lower quality and features some minimal background noise, you should go for a lower amount of epochs (like 15-20 epochs).
If on the other hand you’re certain that your audio source material used for training is of high quality, you can set the number of epochs as high as 200.
A good starting value for quality source vocal samples is anywhere from 150-200 epochs. In our case, we used 150 epochs.
The more epochs in the training process, the longer the training process will take – naturally.
Next setting, the “Batch size per GPU” setting is an important one. The higher the number is, the more VRAM the training process will consume and the faster the training process will be.
To which value you set your batch size, depends on how much GPU memory you can spare without the training process ending abruptly while throwing an “CUDA out of memory”, or any kind of GPU memory limit error.
With 8GB of VRAM, try setting the batch size to around 8, and see if you’re able to train your model without any memory errors. In some cases you will be able to go higher, in some, you will have to lower this number to finish your training successfully. With more VRAM to spare, you can train your models with larger batch sizes. Once again, experimentation is key.
“Save only the latest ‘.ckpt’ file to save disk space” should be set to “yes”, and “Cache all training sets to GPU memory” to “no”.
Last things last, set the “Save a small final model to the ‘weights’ folder at each save point” setting to “yes”.
Now you’re done tweaking all of the most important settings! Click the “Train feature index” button to train the feature index before beginning the model training process (you can also do this afterwards if you want to). Once the process finishes, you can finally train your model.
Simply click the large “Train model” button to begin the model training process. It’s not advised to use the “one-click training” feature, as it’s reported to be unstable in certain cases.
Sit back and relax, while your GPU does the work for you. After the training process is finished (this will be indicated in the terminal window), your model file should be available in the ~\RVC-beta\RVC-beta-[version-number]\weights directory\[your-model-file].pth.
If you’re curious how long the process can take, move on to the next paragraph!
Note: As we’ve mentioned, because of how the RVC WebUI works, the program will save model checkpoint files at set time intervals, so as to help you counter model overfitting and allow you to recover the partial training checkpoints made throughout the training process. These files can quickly add up in size when you train lots of different models, so be sure to remove them after you get your desired voice model, if you’re positive that don’t need them anymore!
Check out also: Quest 2 In The Current Year – Hands On Review (Still Worth It?)
How Long Does It Take To Clone a Voice Using the RVC WebUI?
The length of the training process depends both on the amount of training material used, set number of epochs and the capability of your GPU.
On our system rocking the now not-so-new RTX 2070 SUPER with an efficient 3-fan design, training a model with around 10 minutes of training voice data and 150 epochs took somewhere around 1 hour total.
The less epochs you set, the shorter the training process will be, although at some point while lowering the number of training epochs you may naturally start to lose quality and get worse output.
The larger your batch size, the faster the training process gets, but setting the batch size too high may result in out-of-memory errors if you don’t have enough VRAM (GPU memory) available.
When it comes to model inference, on most modern graphic cards the process can take anywhere from a few seconds for short voicelines, to up to a minute or two for longer audio files.
How To Convert One Voice Into Another (Model Inference)
Now, finally, comes the model inference process, so in more beginner-friendly language, swapping voices, or converting one voice into another. For this, you will need your trained model, as well as a clear audio file with voice recording you wish to change into your trained voice.
The quality requirements for the voice audio file used for inference are pretty much the same as for the training audio, except you can use an audio file of any duration here.
The only important thing here, is that you cannot use an audio file containing any kind of background noise or instrumental parts here.
When it comes to speech, you will need a clear and high quality audio file, and when it comes to songs, a clear acapella without reverb or delay FX applied, and preferably with no vocal harmony going on.
This is a much faster process than the training we just went through, and on most modern hardware it can be almost instantaneous when it comes to shorter audio files. Here is how it goes.
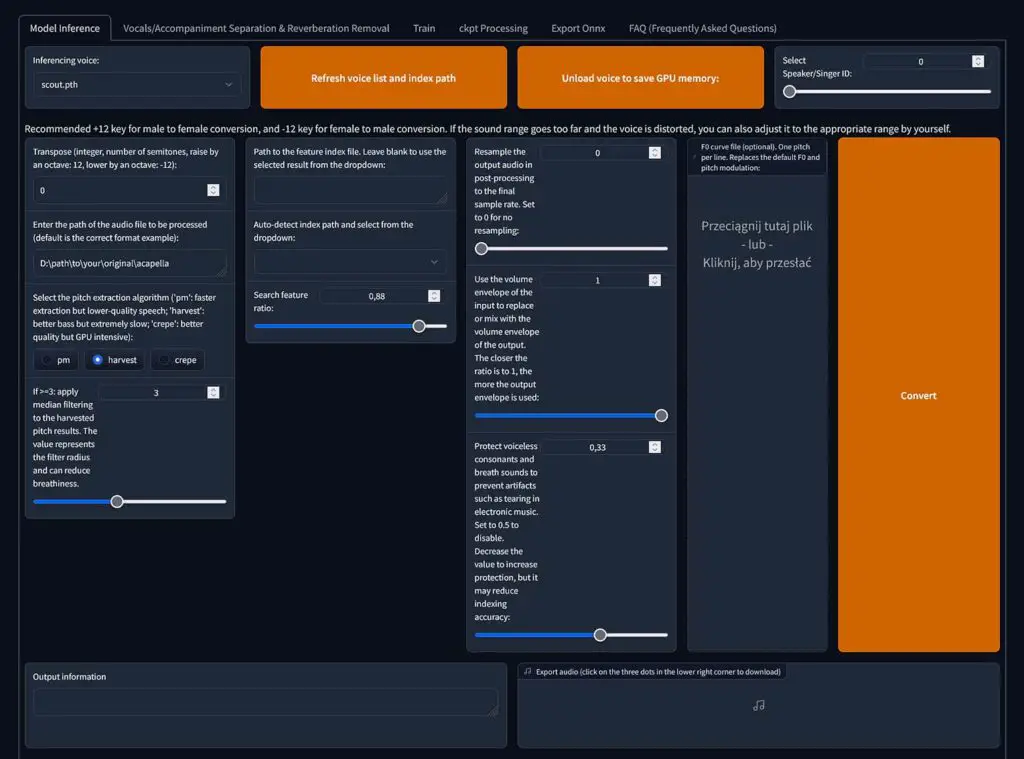
Step 1: Load an RVC voice model of your choice
First, go to the “Model inference” tab, and click the “Refresh voice list and index path” button.
Now, your freshly trained model should show up in the drop-down list on the left side of the window. Click on it to select it.
Then, enter the file path to the audio file with acapella vocals, or a clean, noiseless voice recording you want to convert your chosen voice into. The path to the file goes into the “Enter the path of the audio” field.
Remember, don’t enter the path to the whole directory here – specify the exact file you want to convert at the end of the path.
Note: If you’re attempting to convert a trained voice that is naturally high, to a lower voice, play around with the “transpose” setting to shift the inferred voice up and down in terms of pitch.
Step 2: Enter the settings and convert the voice
Select the “harvest” pitch extraction algorithm, and then in the “Path to the feature index file.” field, from the drop-down menu select the .index file that matches the name of the voice model you’re using (if you don’t have one, you can proceed without it).
You can leave all the other settings as default for now, but feel free to experiment with them later on, if you’d like to further tweak the inference process to get even better results.
Click on the “Convert” button, and sit back until the inference process is finished (typically around a minute or two).
All done! You can now save your audio file output by right clicking on the little audio player that should appear in the WebUI and saving the file in a directory of your choice.
What If I Don’t Have An Acapella File?
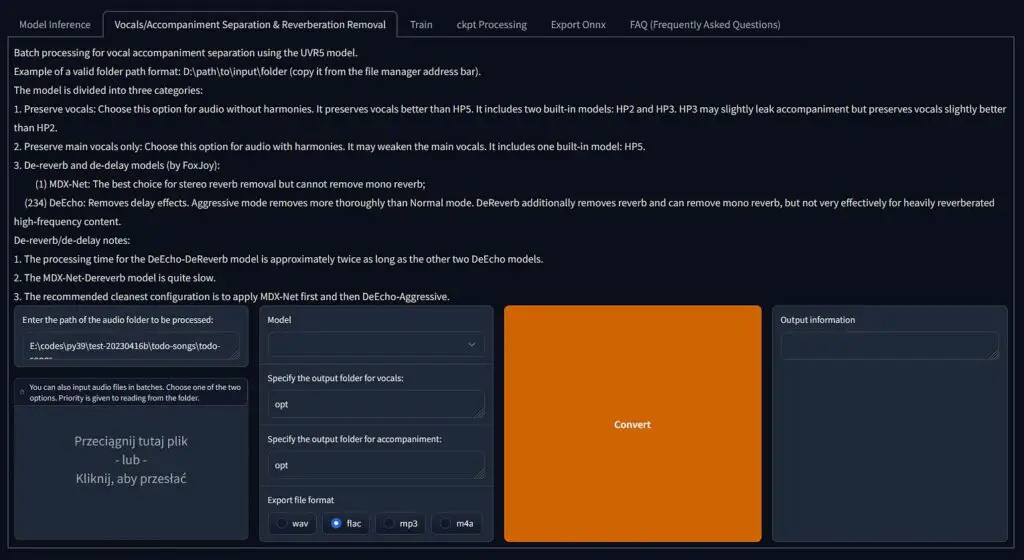
If you don’t have a vocal-only file of the song you want to make an AI voice cover for, your best bet is to either search for a studio acapella for the song online and then use it, or make your own acapella using AI audio isolation tool of your choice.
For making your own acapellas using AI quick and without much trouble, we recommend either using the Ultimate Vocal Remover GUI which is relatively fast and super simple to use, or using the in-built vocal isolation utility which is actually available right inside the RVC WebUI under the “Vocals/Accompaniment Separation & Reverberation Removal” tab.
Attempting to use music audio files with any kind of instruments with them either for training or for inference will result in nonsensical audio output so keep that in mind!
Well, Can I See Some Examples Then? – AI Covers
Certainly! As hinted by in the article thumbnail image, here is a short snippet of Scout from TF2 (Nathan Vetterlein) singing “Bury the light” by Casey Edwards.
As you can hear – not great, not terrible – this is the exact voice output we got out of training our model using the process mentioned above.
We used the freeware Audacity software to add the raw generated acapella vocals to the instrumental file we had on hand.
The vocals go out of tune here and there throughout the whole song, and both the training and inference process could use further settings tweaking, but for our first trained voice, the result is pretty good.
The voice was trained with around 10 minutes of Scout voicelines taken out of Team Fortress 2 sound files.
How To Import Downloaded Voice Models Into RVC?
It’s really easy actually. When you download a custom voice model for example using this wonderful voice model list made by kalomaze (the spreadsheet can run slow, as it’s updated in real time), you will be faced with two files: the model weights, and the feature index file.
Keep in mind that you can only use models that are compatible with RVC/trained using RVC to clone voices using the “Model inference” tab.
To import your downloaded voice model and use it in RVC, you simply need to put the weights file (with .pth extension) into the \weights\ folder, and the index file (with the .index extension) in a folder named exactly the same way as the .pth file, which you’ll have to manually create in the /RVC-beta/logs/ directory. That’s it!
After doing this, you’ll be able to use your imported voices in the RVC WebUI, in the exact same way you’d use your own trained voices. Enjoy!
And That’s It – All Done!
And that’s it – you’ve created your very first cloned voice model and used it to make your very first AI song cover. There is much more to voice cloning than this though!
Keep in mind that this is a basic, bare-bones guide which doesn’t really include any further training and inference optimization, and only offers you starting settings to get you started as quickly as possible.
If you want to know more about RVC and learn more about voice cloning in general, we strongly encourage you to research even more helpful resources on the matter.
One of the resources that is a nice step up from this tutorial is the RVC v2 AI Cover Guide by kalomaze. It makes use of the slightly more efficient Mangio-RVC-Fork, which can yield even better training and inference results!
We hope we were able to help. If you have any questions, don’t hesitate to ask us in the comments below. Until next time!
You might also like: Kinguin Random Game Keys Review – Are They Worth It? (We Bought Some!)



Thanks for sharing. I read many of your blog posts, cool, your blog is very good.